અત્યાર સુધી ગૂગલ સર્ચ એન્જિન આપણે જે સર્ચ કરીએ એ શબ્દો જ પકડી શકતું હતું. હવે નવી ટેક્નોલોજીના પ્રતાપે તે આ શબ્દોના અર્થ અને તેને સંબંધિત બીજી કેટલીય વાતો સમજી શકે છે.
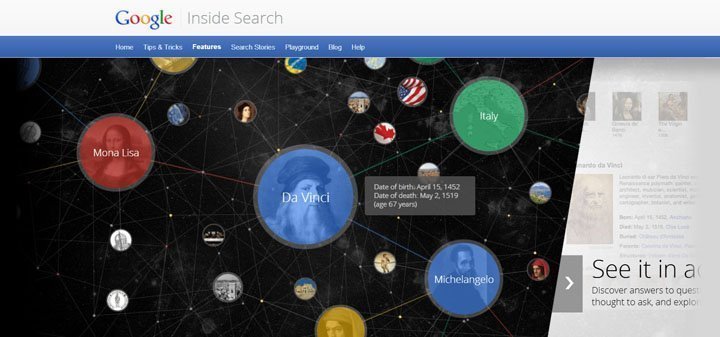 ગયા વર્ષે ગૂગલે તેના સર્ચ એન્જિનમાં એક નવી સુવિધા ઉમેરી હતી – ગૂગલ નોલેજ ગ્રાફ. પહેલી નજરે, આ સુવિધા સાવ સાદી છે – આપણે ગૂગલમાં કોઈ પણ વ્યક્તિ, શહેર કે સંસ્થા વગેરે માટે સર્ચ કરીએ ત્યારે રોજિંદા સર્ચ રીઝલ્ટની સાથોસાથ, સ્ક્રીનમાં ડાબી તરફ એક વિન્ડો ઓપન થાય જેમાં આપણે સર્ચ કરેલી બાબત વિશે વધુ વિગતો હોય. જેમ કે આમીર ખાન વિશે સર્ચ કરીએ તો વિકિપીડિયામાંના તેના લેખનો પ્રારંભિક થોડો ભાગ, તેની ફિલ્મો, ટીવી શો, તેની ઈમેજીસ વગેરે દેખાય. અમદાવાદ વિશે સર્ચ કરીએ તો વિકિપીડિયાના લેખની બે-ત્રણ લીટી ઉપરાંત તેની વસતિ, વિસ્તાર, હવામાન વગેરે માહિતી પણ જોવા મળે.
ગયા વર્ષે ગૂગલે તેના સર્ચ એન્જિનમાં એક નવી સુવિધા ઉમેરી હતી – ગૂગલ નોલેજ ગ્રાફ. પહેલી નજરે, આ સુવિધા સાવ સાદી છે – આપણે ગૂગલમાં કોઈ પણ વ્યક્તિ, શહેર કે સંસ્થા વગેરે માટે સર્ચ કરીએ ત્યારે રોજિંદા સર્ચ રીઝલ્ટની સાથોસાથ, સ્ક્રીનમાં ડાબી તરફ એક વિન્ડો ઓપન થાય જેમાં આપણે સર્ચ કરેલી બાબત વિશે વધુ વિગતો હોય. જેમ કે આમીર ખાન વિશે સર્ચ કરીએ તો વિકિપીડિયામાંના તેના લેખનો પ્રારંભિક થોડો ભાગ, તેની ફિલ્મો, ટીવી શો, તેની ઈમેજીસ વગેરે દેખાય. અમદાવાદ વિશે સર્ચ કરીએ તો વિકિપીડિયાના લેખની બે-ત્રણ લીટી ઉપરાંત તેની વસતિ, વિસ્તાર, હવામાન વગેરે માહિતી પણ જોવા મળે.
આપણને લાગે કે આમાં શું મોટી વાત છે? આ બધી વિગતો ગૂગલ જાણે જ છે, આપણે સર્ચ કરતાં એ બધું સાથે લાવીને મૂકે છે, બસ એટલું જ. પણ ના, નિષ્ણાતો કહે છે કે અત્યારે ભલે ગૂગલની આ નવી સુવિધા સાવ પ્રાથમિક તબક્કામાં હોય, ભવિષ્યમાં એ ઇન્ટરનેટ સર્ચિંગમાં ધરમૂળથી ક્રાંતિ લાવી દેશે.
કેમ?

આ સવાલનો જવાબ જાણવા માટે આપણે પહેલાં તો અત્યાર સુધી ગૂગલ કઈ રીતે સર્ચ કરે છે એ સમજવું પડે.
આપણે એટલું તો બરાબર જાણીએ છીએ કે આપણે કોઈ પણ સર્ચ એન્જિનમાં કોઈ પણ શબ્દ કે વાક્ય સર્ચ કરીએ એટલે એને વિશે માહિતી ધરાવતાં વેબપેજીસનું લાંબુંલચક લિસ્ટ આપણને જોવા મળે છે.
આ લિસ્ટ તૈયાર કઈ રીતે થાય છે?
આ લિસ્ટ તૈયાર કરવા માટે કોઈ પણ સર્ચ એન્જિને મુખ્ય ત્રણ પ્રકારનાં કામ કરવાં પડે છે. સૌથી પહેલાં, ઇન્ટરનેટ પરનાં શક્ય એટલાં બધાં વેબપેજીસમાં આંટો મારીને (ક્રાઉલિંગ કરીને) તેમાં રહેલી બાબતો તપાસવી પડે. પછી તેનું ઇન્ડેક્સિગં કરવું પડે, એટલે કે કયા વેબપેજમાં શું છે તેની યાદી તૈયાર કરવી પડે અને પછી જુદા જુદા માપદંડોને આધારે સર્ચ રીઝલ્ટમાં કયા પેજને સૌથી આગળ મૂકવું તે નક્કી કરવા તેનું રેન્કિંગ કરવું પડે.
સાવ શરુઆતના તબક્કામાં ગૂગલનું સર્ચ એન્જિન પહેલા ક્રમનું કામ – ઇન્ટરનેટનાં બધાં પેજ તપાસવા માટે લગભગ ૩૦ દિવસનો સમય લેતું હતું. એ પછી આ બધાં વેબપેજીસમાં કઈ માહિતી છે તેનું ઇન્ડેક્સિગં કરવામાં વધુ એક અઠવાડિયા જેટલો સમયજાય. પછીના એકાદ અઠવાડિયામાં એ બધી માહિતી સર્ચ એન્જિનમાં પહોંચે અને આપણે જ્યારે સર્ચ કરીએ ત્યારે પેલી બધી માહિતીને આધારે આપણને પરિણામ જાણવા મળે. ત્યારે એવું બનતું કે કોઈ વેબપેજમાં બહુ જૂની માહિતી હોય તો કેટલાકમાં નવી માહિતી હોય.
આથી સર્ચને વધુ અસરકારક બનાવવા માટે, ગૂગલે બધાં વેબપેજીસનું ૩૦ દિવસ સુધી ક્રાઉલિંગ કર્યા પછી જે વેબપેજનો પેજ રેન્ક ઊંચો હોય તેનું ફરી ક્રાઉલિંગ કરવાનું શરુ કર્યું.
હવે આ પેજ રેન્કની નવી વાત ઉમેરાઈ. કયા વેબપેજનો પેજ રેન્ક ઊંચો એ કેવી રીતે નક્કી થાય? એનું વળી પાછું જુદું ગણિત છે. તેના જુદા જુદા માપદંડો હોય છે, પણ સાામાન્ય રીતે વધુ મુલાકાતીઓ અને બીજી સાઇટ્સ પરથી જેને વધુ લિંક્સ મળી હોય એ પેજીસને ઊંચો પેજ રેન્ક મળે (તમારી સાઇટની લિંક આપનારી સાઇટ પોતે કેટલી પ્રતિષ્ઠિત છે એ પણ આમાં તપાસવામાં આવે). પરંતુ આ બધામાં છેવટે તો ઓછામાં ઓછા ત્રીસેક દિવસનો સમય જતો હતો એટલે સરવાળે, આપણે જ્યારે સર્ચ કરીએ ત્યારે આપણને જાણવા મળતાં પરિણામ બહુ સચોટ ન હોય એવું બનતું હતું.

લગભગ ૨૦૦૩ના અરસાથી સ્થિતિ બદલાઈ. ગૂગલે ઊંચા પેજરેન્કિંગ ધરાવતા પેજીસને સર્ચ રીઝલ્ટમાં આગળ મૂકવાનું તો ચાલુ જ રાખ્યું, પણ બધાં વેબપેજીસનું ક્રાઉલિંગ કરવાની પદ્ધતિ બદલી. ગૂગલે વેબજગતને વિવિધ ભાગમાં વહેંચીને દરેકનું એક સાથે ક્રાઉલિંગ કરવાનું ચાલુ કર્યું, જેને દરરોજ રાત્રે રીફ્રેશ કરવામાં આવે. મતલબ કે આખા વેબજગતનું ક્રાઉલિંગ પૂરું થાય અને પછી ઇન્ડેક્સિગં શરૂ થાય એને બદલે રોજેરોજ ઇન્ડેક્સિગં થાય, તેથી સર્ચ સમયે જોવા મળતાં રીઝલ્ટ માંડ એકાદ દિવસ જેટલાં જ જૂનાં હોય. એ પછી જ ગૂગલે પોતાની સિસ્ટમ વધુ ને વધુ સુધારી અને વેબપેજીસમાં થતા ચેન્જીસ બહુ ઝડપથી ગૂગલના સર્ચ એન્જિનમાં અપડેટ થવા લાગ્યા.
આ વાત થઈ જુદાં જુદાં અસંખ્ય વેબપેજીસમાં શું છે તે જાણવા માટે તેમાં ચક્કર લગાવવાની. પછીનું કામ છે આ માહિતીની યોગ્ય અને વ્યવસ્થિત રીતે નોંધ કરવાનું, એટલે કે ઇન્ડેક્સિગં કરવાનું.
આ સમજવા એક ઉદાહરણ લઈએ. ધારો કે આપણે ગૂગલમાં ‘નરેન્દ્ર મોદી’ સર્ચ કરીએ છીએ, તો ગૂગલ તેનાં રીઝલ્ટ આપણને કઈ રીતે બતાવશે? એ માટે ગૂગલને માહિતી હોવી જોઈએ કે કે કયાં કયાં વેબ પેજીસમાં નરેન્દ્ર અને મોદી બંને શબ્દો છે. અમુક વેબ પેજમાં આ બંને શબ્દો સાથે સાથે હોય, અમુકમાં ફક્ત નરેન્દ્ર મળે અને અમુકમાં ફક્ત મોદી મળે. ગૂગલનાં એન્જિન આ બધાની નોંધ કરે.
પછી સૌથી છેલ્લો, પણ સૌથી મહત્ત્વનો તબક્કો આવે, આ બધાં પેજીસમાંથી સૌથી ઉપરથી ઊતરતા ક્રમમાં કેવી રીતે ગોઠવવાં? આથી ગૂગલ સૌથી પહેલાં તો જેમાં નરેન્દ્ર અને મોદી બંને શબ્દ ન હોય એવાં પેજીસ બાકાત કરશે. પછી ફક્ત નરેન્દ્ર કે ફક્ત મોદી હોય એવાં પેજીસને પાછળ ધકેલશે. પછી, એ પેજ પરના લખાણમાં કે ઇમેજના ટાઇટલમાં (જે વેબસાઇટ પર એક પેજમાં આપણને દેખાય છે), એ પેજ કે ઇમેજ વિશેના વિશેના વર્ણનમાં (જેને મેટાડેટા કહે છે, જે આપણને વેબસાઇટ પર દેખાતું નથી) વગેરેમાં નરેન્દ્ર અને મોદી બંનેનો ઉલ્લેખ હોય તેવાં પેજીસ અલગ તારવે છે. આ બધાં પેજીસના પેજ રેન્ક તપાસવામાં આવે છે. તે ઉપરાંત, લગભગ ૨૦૦ જેટલા માપદંડથી આ દરેક પેજને તપાસીને તેને ઉપરથી નીચેનો ક્રમ આપવામાં આવે છે!
આ આખી પ્રક્રિયા શક્ય એટલી સરળ રીતે લખી હોવા છતાં ગૂંચવણભરી લાગી હશે, પણ વાસ્તવમાં તો કેટલીય વધુ જટિલ છે.
અત્યારની પરિસ્થિતિ સમજવી હોય તો એવું કહી શકાય કે દરરોજ લાખો-કરોડો લોકો ગૂગલના સર્ચ એન્જિન પર જઈને એક શબ્દથી માંડીને આખેઆખાં વાક્યો લખીને તેની માહિતી સર્ચ કરે છે. આ ક્ષણે ગૂગલ આ સર્ચ ક્વેરી એક સાથે અસંખ્ય મશીનોમાં મોકલે છે. આ દરેક મશીન, તેમણે કરેલા ક્રાઉલિંગ અને ઇન્ડેક્સિગં અનુસાર, તેમના અભિપ્રાય અનુસાર સૌથી સચોટ હોય તેવાં પરિણામો મોકલે છે. તેમાં ગૂગલ સૌથી બંધબેસતાં રીઝલ્ટ નક્કી કરીને આપણી સમક્ષ મૂકે છે. આખી વાત ખરેખર ઘાસની કેટકેટલીય ગંજીઓમાંથી સોય શોધી લાવવા જેવું છે.
આટલા સંદર્ભ પછી, હવે મૂળ વાત પર પરત ફરીએ. ગૂગલે રજૂ કરેલી નવી સુવિધા નોલેજ ગ્રાફ કેમ બહુ મોટી શોધ મનાય છે?
તેનું કારણ એ છે કે આ સુવિધાની શરુઆત થઈ તે પહેલાં, એક રીતે જોઈએ તો, ગૂગલને ખબર જ નહોતી પડતી કે નરેન્દ્ર અને મોદી શું છે? તેને માટે એ બે શબ્દ માત્ર છે, ગૂગલની ભૂમિકા અસંખ્ય વેબપેજીસમાંથી આ બે શબ્દ ધરાવતાં પાનાં શોધીને, યોગ્ય માપદંડોથી તપાસીને આપણી સમક્ષ મૂકવાનું પૂરતું સીમિત હતું.
બીજી રીતે કહીએ તો આપણે ‘ન્યૂ યોર્ક’ સર્ચ કરીએ ત્યારે ગૂગલને એ ખબર નહોતી પડતી કે ન્યુ યોર્ક એક શહેર છે અને તેને સંબંધિત કેટલીક માહિતી તેની પાસે છે.
નોલેજ ગ્રાફ સર્ચથી, ગૂગલે આપણે જે શબ્દો સર્ચ કરીએ, તેના અર્થ સમજવાનું પણ શરૂ કર્યુ છે. હવે તેને ‘સમજાય’ છે કે ન્યૂ અને યોર્ક શબ્દ સાથે હોય એ ફક્ત કોરા શબ્દો નથી, એ નામનું એક શહેર છે, જ્યાં વસતિ છે, જેનો વિસ્તાર છે, જ્યાં જોવાલાયક પ્રવાસન સ્થળો છે, જ્યાં ચોક્કસ હવામાન છે, જ્યાં જુદી જુદી ઇવેન્ટ્સ યોજાય છે… અને આ બધું જ જાણવામાં ન્યૂ યોર્ક શબ્દ સર્ચ કરનારા લોકોને રસ હોઈ શકે છે!
હવે જો આપણે ગૂગલમાં ‘તાજ મહાલ’ સર્ચ કરીએ તો ગૂગલને ખબર હોય છે કે આ નામે ભારતમાં એક જગપ્રસિદ્ધ ઇમારત છે, આ જ નામે કોઈએ મ્યુઝિકનું બેન્ડ શરુ કર્યું છે અને અમેરિકામાં તાજ મહાલ નામનું એક જુગારખાનું પણ છે! એટલે ગૂગલ તેના નોલેજ ગ્રાફમાં આ ત્રણેય બાબતોને અલગ અલગ તારવીને તેને લગતી જુદી જુદી માહિતી આપણને આપશે.
આમ તો આટલે સુધી સમજ્યા પછી પણ, આપણે ગૂગલ સર્ચના રીઝલ્ટ પેજ પર નોલેજ ગ્રાફનાં રીઝલ્ટ જોઈએ તો સામાન્ય સર્ચ રીઝલ્ટ અને આ નોલેજ ગ્રાફ વચ્ચે ખાસ કોઈ મોટો – ક્રાંતિકારી – તફાવત હોય એવું લાગતું નથી, પણ આ પ્રક્રિયામાં સિંહફાળો આપનારા ગૂગલના સિનિયર વાઇસ પ્રેસિડેન્ટ અને મૂળ ભારતીય અમિત સિંઘલ કહે છે કે નોલેજ ગ્રાફનાં અત્યારનાં પરિણામોથી તેની શક્તિનો કાચો અંદાજ બાંધવાની ભૂલ કરશો નહીં. તેમના મતે, આ તો કોઈ વિશ્વવિખ્યાત ચિત્રકારની સર્જનાત્મકતાને, તેઓ એક-બે વર્ષના હોય ત્યારે જે ચિતરામણ કરતા હોય તેનાથી આંકવા જેવું થશે. ગૂગલના સ્થાપક લેરી પેજે પણ થોડા સમય પહેલાં કહ્યું હતું કે નોલેજ ગ્રાફના મામલે ‘અમે જ્યાં પહોંચવા માગીએ છીએ તેના માંડ ૧ ટકા સુધી જ પહોંચી શક્યા છીએ.’
અત્યારે ગૂગલે ૫૦ કરોડ જેટલા લોકો ને સ્થળો વગેરે જેવી બાબતોની ‘સમજ’ કેળવવાની અને આ બધા વચ્ચે સાડા ત્રણ અબજ જેટલાં કનેક્શન કરવાની ક્ષમતા મેળવી લીધી છે. આપણું મગજ જે જુએ છે એના અર્થ કુદરતી રીતે જ તારવી શકે છે. કંઈક આવું જ કામ ગૂગલ નોલેજ ગ્રાફથી કમ્પ્યુટર્સ કરશે એવી ધારણા છે.
નોલેજ ગ્રાફમાં સિંહફાળો આપનારા ભારતીય
 ગૂગલ નોલેજ ગ્રાફના ડેવલપમેન્ટમાં તેના સિનિયર વાઇસ પ્રેસિડેન્ટ અને ગૂગલ ફેલો અમિત સિંઘલનો સિંહફાળો છે. ભારતમાં જન્મેલા અમિતે તેમનું બાળપણ ઉત્તર પ્રદેશમાં હિમાલયની ગોદમાં વિતાવ્યું. યુનિવર્સિટી ઓફ રુરકી (હાલમાં આઇઆઇટી રુરકી)માં કમ્પ્યુટર સાયન્સમાં ડીગ્રી મેળવીને તેમણે એ જ વિષયમાં એમએસની ડીગ્રી મેળવી. પછી અમેરિકાની કોર્નેલ યુનિવર્સિટીમાં પીએચ.ડી.ની ડીગ્રી મેળવી.
ગૂગલ નોલેજ ગ્રાફના ડેવલપમેન્ટમાં તેના સિનિયર વાઇસ પ્રેસિડેન્ટ અને ગૂગલ ફેલો અમિત સિંઘલનો સિંહફાળો છે. ભારતમાં જન્મેલા અમિતે તેમનું બાળપણ ઉત્તર પ્રદેશમાં હિમાલયની ગોદમાં વિતાવ્યું. યુનિવર્સિટી ઓફ રુરકી (હાલમાં આઇઆઇટી રુરકી)માં કમ્પ્યુટર સાયન્સમાં ડીગ્રી મેળવીને તેમણે એ જ વિષયમાં એમએસની ડીગ્રી મેળવી. પછી અમેરિકાની કોર્નેલ યુનિવર્સિટીમાં પીએચ.ડી.ની ડીગ્રી મેળવી.
આ બધા અભ્યાસ દરમિયાન એમણે ઇન્ફર્મેશન રીટ્રીવલ (આઇઆર)ના ક્ષેત્રમાં અને વેબ સર્ચ, વેબ ગ્રાફ એનાલિસિસ, સર્ચ માટેના યુઝર ઇન્ટરફેસીસ વગેરેમાં સંશોધન અને નોકરી બંને ચાલુ રાખ્યાં. એટીએન્ડટી કંપનીમાં નોકરી કર્યા પછી વર્ષ ૨૦૦૦માં તેઓ ગૂગલમાં જોડાયા. અમેરિકાની નેશનલ એકેડમી ઓફ એન્જિનીયરિંગમાં એક સભ્ય તરીકે જોડાવાનું સન્માન પણ તેમને મળ્યું છે.
ગૂગલ નોલેજ ગ્રાફ ફક્ત કોરા શબ્દો નહીં, તેની પાછળના અર્થ અને બીજા શબ્દો તથા માહિતી સાથેના તેના સંબંધો સમજવાની એક વિરાટ કસરત છે.
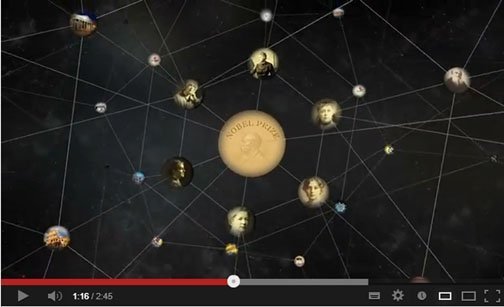 સામાન્ય રીતે, આપણે જ્યારે ગૂગલમાં કંઈ પણ સર્ચ કરીએ ત્યારે ગૂગલ એ શબ્દો ધરાવતાં વેબપેજીસનું લાંબુ લિસ્ટ આપણી સામે ધરી દે છે. વાસ્તવમાં આપણને વેબપેજીસમાં રસ હોતો નથી. આપણને તો આપણા પ્રશ્નોના જવાબો જોતા હોય છે, આપણે આપણે સર્ચ કરેલી બાબત સમજવા માગતા હોઈએ છીએ, અથવા તો એ વિશે આપણને કલ્પના પણ ન હોય એવું બધું આપણે જાણવા માગતા હોઈએ છીએ. ગૂગલે આ મુદ્દો સમજીને, વિશ્વની અનેક બાબતો અને તેમની વચ્ચેના સંબંધોનો એક વિશાળ ગ્રાફ બનાવવાની શરૂઆત કરી છે. જેને કારણે ગૂગલ આપણી જરુર સમજીને, આપણી કલ્પના કરતાં વધુ માહિતી આપણને આપી શકશે.
સામાન્ય રીતે, આપણે જ્યારે ગૂગલમાં કંઈ પણ સર્ચ કરીએ ત્યારે ગૂગલ એ શબ્દો ધરાવતાં વેબપેજીસનું લાંબુ લિસ્ટ આપણી સામે ધરી દે છે. વાસ્તવમાં આપણને વેબપેજીસમાં રસ હોતો નથી. આપણને તો આપણા પ્રશ્નોના જવાબો જોતા હોય છે, આપણે આપણે સર્ચ કરેલી બાબત સમજવા માગતા હોઈએ છીએ, અથવા તો એ વિશે આપણને કલ્પના પણ ન હોય એવું બધું આપણે જાણવા માગતા હોઈએ છીએ. ગૂગલે આ મુદ્દો સમજીને, વિશ્વની અનેક બાબતો અને તેમની વચ્ચેના સંબંધોનો એક વિશાળ ગ્રાફ બનાવવાની શરૂઆત કરી છે. જેને કારણે ગૂગલ આપણી જરુર સમજીને, આપણી કલ્પના કરતાં વધુ માહિતી આપણને આપી શકશે.
જુઓ વીડિયોઃ http://youtu.be/mmQl6VGvX-c